From Basics to Application: A Deep Dive into Convolutional Neural Networks

I am currently serving as an Assistant Professor at CHRIST (Deemed to be University), Bangalore. With a Ph.D. in Information and Communication Engineering from Anna University and ongoing post-doctoral research at the Singapore Institute of Technology, her expertise lies in Ethical AI, Edge Computing, and innovative teaching methodologies. I have published extensively in reputed international journals and conferences, hold multiple patents, and actively contribute as a reviewer for leading journals, including IEEE and Springer. A UGC-NET qualified educator with a computer science background, I am committed to fostering impactful research and technological innovation for societal good.
🚀 Introduction
Have you ever wondered how your phone recognizes faces, how self-driving cars detect objects, or how Google Photos organizes images? The secret lies in Convolutional Neural Networks (CNNs). CNNs are a type of deep learning model designed to process images by automatically learning patterns like edges, shapes, colors, and even objects.
Computer vision has undergone a remarkable transformation over the past decade, with CNNs at the forefront of this revolution. In 2025, CNNs continue to be the backbone of most computer vision applications, from medical diagnosis to autonomous vehicles, despite the emergence of Vision Transformers. This comprehensive guide will take you from CNN fundamentals to hands-on implementation, incorporating the latest research perspectives and practical applications. The image shows samples of handwritten digits from the MNIST dataset used for CNN classification tasks

🧩 What are Convolutional Neural Networks?
A Convolutional Neural Network (CNN) is a specialized type of neural network designed to process data with a grid-like topology, particularly images. Unlike traditional neural networks that treat input data as flat vectors, CNNs preserve the spatial relationships between pixels, making them exceptionally effective for visual recognition tasks.
⚖️ Key Differences from Traditional Neural Networks
| Aspect | Traditional Neural Networks | Convolutional Neural Networks |
| Input Processing | Flattens input into 1D vector | Preserves 2D/3D spatial structure |
| Parameter Sharing | Each connection has unique weights | Shared weights across spatial locations |
| Translation Invariance | Not inherently translation invariant | Naturally handles object position variations |
| Computational Efficiency | High parameter count | Reduced parameters through weight sharing |
📌CNN Architecture: Layer by Layer
The Five Essential Layers
CNNs consist of five fundamental layer types that work together to extract features and make predictions:
1. Input Layer: Accepts raw pixel values from images, typically represented as a three-dimensional tensor (height × width × depth). For example, a color image with dimensions 100×100 pixels has a shape of 100×100×3 (RGB channels).
2. Convolutional Layers: The core building blocks that apply convolution operations using filters (kernels) to detect features like edges, textures, and shapes. Each filter produces a feature map highlighting specific patterns in the input data.
3. Activation Layers: Apply non-linear functions like ReLU (Rectified Linear Unit) to introduce non-linearity, enabling the network to learn complex patterns.
4. Pooling Layers: Reduce spatial dimensions while preserving essential features, typically using max pooling or average pooling operations.
5. Fully Connected Layers: Convert extracted features into final predictions, similar to traditional neural networks.
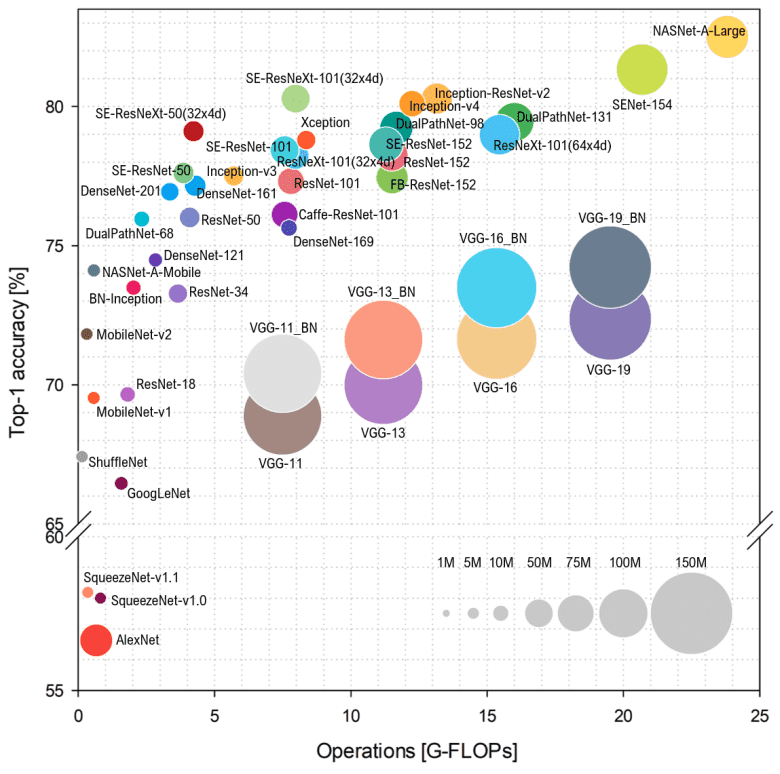
This bubble chart compares the popular CNN architectures by top-1 accuracy and computational cost with parameter sizes represented by bubble size
🎯 Mathematical Foundations: Understanding Convolution
The convolution operation is the mathematical foundation of CNNs. It involves sliding a filter (kernel) across the input image and computing the dot product at each position:
Convolution Formula
For an input image I and filter K, the convolution operation at position (i,j) is:
$$(I∗K)(i,j)=∑_m ∑_n I(i+m,j+n)⋅K(m,n)$$
Key Parameters
Filter Size: Typically 3×3, 5×5, or 7×7
Stride: Step size for filter movement (usually 1 or 2)
Padding: Adding zeros around input borders to control output size
Number of Filters: Determines the depth of output feature maps
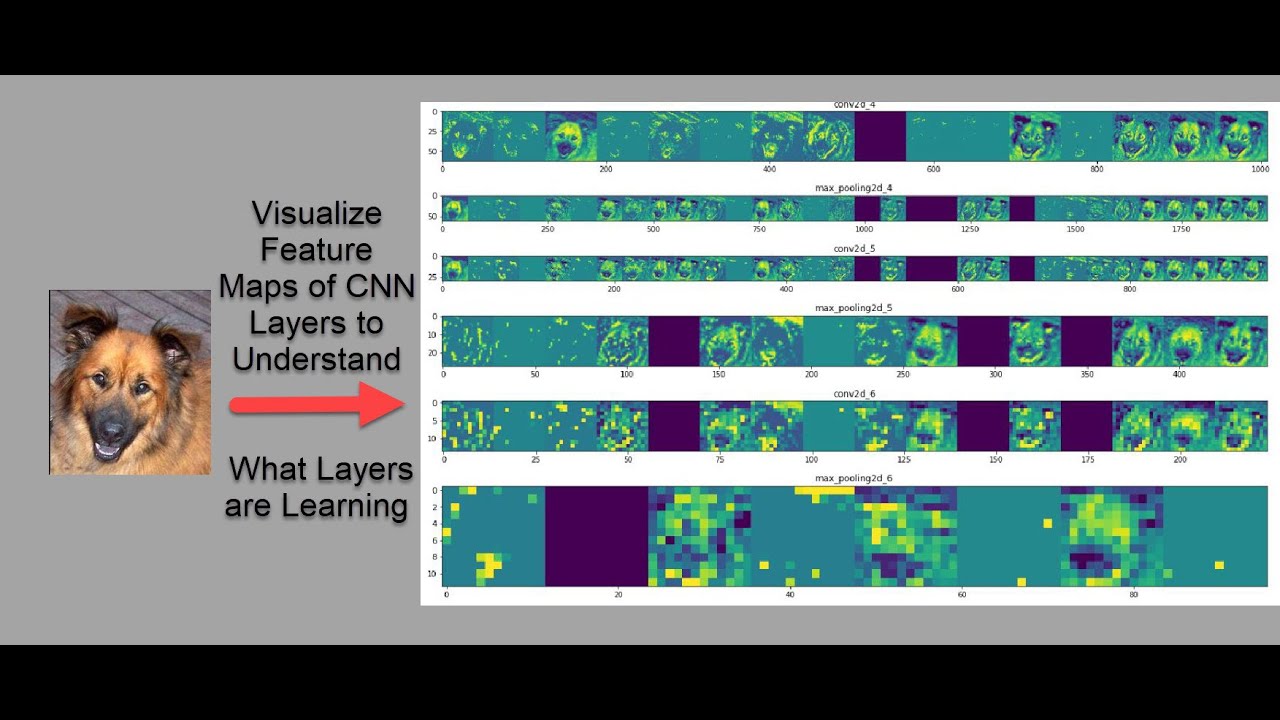
Based on building block layers of a CNN, the image visualizes the feature maps across convolutional and pooling layers to understand the learned features by the network.
💻 Building Blocks in Detail
Convolutional Layers
Convolutional layers detect patterns through learnable filters. Modern CNNs use several variations:
Standard Convolution: Basic convolution operation
Dilated Convolution: Increases receptive field without additional parameters
Depthwise Separable Convolution: Reduces computational complexity
1×1 Convolution: Dimensionality reduction and feature combination
Pooling Operations
Pooling layers reduce computational complexity and provide translation invariance:
Max Pooling: Selects maximum value in each region
Average Pooling: Computes average of values in each region
Global Average Pooling: Reduces entire feature map to single value
Activation Functions
Modern CNNs primarily use ReLU (Rectified Linear Unit) activation due to its effectiveness in preventing vanishing gradients:
$$ReLU(x)=max(0,x)$$
Other variants include:
Leaky ReLU: Allows small negative values
ELU: Exponential Linear Unit for smoother gradients
Swish: Self-gated activation function
🔸🔹 Popular CNN Architectures: Evolution and Comparison
| Architecture | Year | Key Innovation | Parameters | Top-1 Accuracy |
| LeNet-5 | 1998 | First successful CNN | 60K | ~99% (MNIST) |
| AlexNet | 2012 | Deep CNN with ReLU | 62M | 84.7% (ImageNet) |
| VGG-16 | 2014 | Very deep networks | 138M | 92.7% (ImageNet) |
| GoogLeNet | 2014 | Inception modules | 7M | 93.3% (ImageNet) |
| ResNet-50 | 2015 | Skip connections | 25M | 96.4% (ImageNet) |
✨ Modern Architecture Highlights
ResNet (Residual Networks): Introduced skip connections to enable training of very deep networks (up to 1000+ layers). The key innovation is the residual block:
$$H(x)=F(x)+x$$
VGG Networks: Demonstrated that network depth is crucial for performance, using small 3×3 filters throughout.
Inception/GoogLeNet: Introduced multi-scale feature extraction through inception modules, significantly reducing parameters while maintaining performance.
🏆 Latest Research and Trends in 2025
CNN vs Vision Transformers
Recent research has intensively compared CNNs with Vision Transformers (ViTs). Key findings include:
Performance: ViTs show superior performance on large datasets, while CNNs excel on smaller datasets
Data Requirements: ViTs require significantly more training data
Computational Efficiency: CNNs remain more efficient for many practical applications
Interpretability: Both architectures offer different interpretability advantages
Attention Mechanisms in CNNs
Modern CNN architectures increasingly incorporate attention mechanisms:
Spatial Attention: Focuses on important spatial locations
Channel Attention: Emphasizes relevant feature channels
Self-Attention: Captures long-range dependencies within images
🔬 Recent Advances
Efficient CNNs: Research focuses on reducing computational requirements while maintaining accuracy:
MobileNets: Optimized for mobile devices
EfficientNets: Balanced scaling of network dimensions
Neural Architecture Search: Automated design optimization
Specialized Applications: CNNs continue advancing in specific domains:
Medical Imaging: Achieving expert-level diagnostic accuracy
Environmental Monitoring: Real-time satellite image analysis
Autonomous Systems: Enhanced safety through robust perception
🧠 Hands-on Tutorial: Building Your First CNN
Let's implement a complete CNN for MNIST digit classification using TensorFlow and Keras.
Step 1: Environment Setup
# Import necessary libraries
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
# Set random seed for reproducibility
tf.random.set_seed(42)
np.random.seed(42)
print(f"TensorFlow version: {tf.__version__}")
Step 2: Data Loading and Exploration
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
print(f"Training data shape: {x_train.shape}")
print(f"Training labels shape: {y_train.shape}")
print(f"Test data shape: {x_test.shape}")
print(f"Test labels shape: {y_test.shape}")
# Visualize sample images
plt.figure(figsize=(12, 8))
for i in range(12):
plt.subplot(3, 4, i + 1)
plt.imshow(x_train[i], cmap='gray')
plt.title(f'Label: {y_train[i]}')
plt.axis('off')
plt.tight_layout()
plt.show()
Step 3: Data Preprocessing
# Normalize pixel values to [0, 1]
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# Reshape data to add channel dimension
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# Convert labels to categorical
y_train_cat = to_categorical(y_train, 10)
y_test_cat = to_categorical(y_test, 10)
print(f"Preprocessed training data shape: {x_train.shape}")
print(f"Preprocessed labels shape: {y_train_cat.shape}")
Step 4: CNN Architecture Design
# Build CNN model
model = models.Sequential([
# First Convolutional Block
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
# Second Convolutional Block
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# Third Convolutional Block
layers.Conv2D(64, (3, 3), activation='relu'),
# Classifier
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dropout(0.5), # Regularization
layers.Dense(10, activation='softmax')
])
# Display model architecture
model.summary()
Step 5: Model Compilation
# Compile the model
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
Step 6: Training with Validation
# Train the model
history = model.fit(
x_train, y_train_cat,
epochs=10,
batch_size=128,
validation_split=0.2,
verbose=1
)
Step 7: Model Evaluation
# Evaluate on test set
test_loss, test_accuracy = model.evaluate(x_test, y_test_cat, verbose=0)
print(f"Test Accuracy: {test_accuracy:.4f}")
# Generate predictions
predictions = model.predict(x_test[:10])
predicted_labels = np.argmax(predictions, axis=1)
# Visualize predictions
plt.figure(figsize=(15, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i].reshape(28, 28), cmap='gray')
plt.title(f'True: {y_test[i]}, Pred: {predicted_labels[i]}')
plt.axis('off')
plt.tight_layout()
plt.show()
Step 8: Training Visualization
# Plot training history
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
Step 9: Advanced Experimentation
# Experiment with different architectures
def create_deeper_cnn():
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.BatchNormalization(),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Dropout(0.25),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.BatchNormalization(),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Dropout(0.25),
layers.Conv2D(128, (3, 3), activation='relu'),
layers.BatchNormalization(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(0.5),
layers.Dense(10, activation='softmax')
])
return model
# Create and train the deeper model
deeper_model = create_deeper_cnn()
deeper_model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
print("Deeper CNN Architecture:")
deeper_model.summary()
🌐 Practical Applications: Real-World Impact
🧬 Medical Imaging Revolution
CNNs have revolutionized medical diagnosis, achieving expert-level accuracy in various applications:
Diagnostic Applications:
Cancer Detection: CNNs analyze mammograms, CT scans, and MRI images to detect tumors with 95%+ accuracy
Chest X-ray Analysis: Models like CheXNet classify 14 different chest conditions, often outperforming radiologists
Retinal Disease Detection: Automated screening for diabetic retinopathy using fundus photographs
Performance Metrics: Recent studies show CNNs achieving 96.68% training accuracy and 93.10% testing accuracy for pneumonia detection from chest X-rays.
🚗 Autonomous Vehicle Technology
CNNs form the visual perception backbone of self-driving cars:
Core Functions:
Lane Detection: Real-time identification of road boundaries and lane markings
Object Recognition: Detection and classification of vehicles, pedestrians, traffic signs
Obstacle Avoidance: Spatial awareness and path planning in complex environments
Technical Implementation: Modern autonomous systems use multi-scale CNN architectures processing camera, LiDAR, and radar data simultaneously.
🛍️ Consumer and Industrial Applications
E-commerce and Social Media:
Visual Search: Product discovery through image uploads
Content Moderation: Automated detection of inappropriate content
Recommendation Systems: Image-based product suggestions
Industrial Quality Control:
Defect Detection: Microscopic flaw identification in manufacturing
Agricultural Monitoring: Crop health assessment from satellite imagery
Scientific Research: Particle physics data analysis in accelerator experiments
✅ Best Practices for CNN Development
Training Optimization
Data Preparation:
Normalization: Scale pixel values to or [-1,1] range
Data Augmentation: Rotation, scaling, flipping to increase dataset diversity
Proper Train/Validation/Test Splits: Typically 70/15/15 or 80/10/10
Architecture Design:
Start Simple: Begin with basic architectures and gradually increase complexity
Regularization: Use dropout (0.2-0.5) and batch normalization
Appropriate Filter Sizes: 3×3 filters are most common and effective
⚠️ Avoiding Common Pitfalls
Overfitting Prevention:
Early Stopping: Monitor validation loss and stop when it plateaus
Cross-Validation: Use k-fold validation for robust performance estimates
Learning Rate Scheduling: Reduce learning rate when validation loss stagnates
Performance Monitoring:
Multiple Metrics: Track accuracy, precision, recall, and F1-score
Confusion Matrices: Identify specific classification errors
Feature Visualization: Understand what filters learn at different layers
🛠️ Hyperparameter Tuning
| Parameter | Typical Range | Impact |
| Learning Rate | 0.0001 - 0.01 | Training speed and convergence |
| Batch Size | 16 - 128 | Memory usage and gradient stability |
| Number of Filters | 32 - 512 | Feature extraction capacity |
| Filter Size | 3×3 - 7×7 | Receptive field and detail capture |
🔮 Future Directions and Emerging Trends
Hybrid Architectures
The future of computer vision lies in combining the strengths of different architectures:
CNN-Transformer Hybrids: Leveraging local feature extraction and global attention
Multi-Modal Networks: Integrating visual, textual, and audio information
Neural Architecture Search: Automated optimization of network designs
Efficient Computing
Edge AI Development:
Quantization: Reducing model precision for faster inference
Pruning: Removing unnecessary network connections
Knowledge Distillation: Creating smaller models that mimic larger ones
Sustainability and Ethics
Environmental Considerations:
Green AI: Developing energy-efficient training methods
Model Reuse: Transfer learning and pre-trained model utilization
Responsible Deployment: Considering bias and fairness in CNN applications
Steps for Continued Learning
Immediate Actions:
Experiment: Modify the provided code with different datasets (CIFAR-10, Fashion-MNIST)
Explore: Try implementing other architectures (ResNet, VGG, Inception)
Compete: Participate in Kaggle competitions to apply your skills
Advanced Learning Paths:
Specialized Applications: Focus on medical imaging, autonomous systems, or NLP
Research Frontiers: Explore Vision Transformers, self-supervised learning, or neural architecture search
Production Deployment: Learn MLOps, model serving, and edge deployment
🌟 Wrap-Up
The field of computer vision continues evolving rapidly, but with this solid CNN foundation, you're well-equipped to adapt to new developments and contribute to the next wave of innovations. Whether you're interested in saving lives through medical AI, enhancing safety with autonomous systems, or creating the next breakthrough in visual understanding, CNNs provide the essential building blocks for your journey.
Remember: the best way to master CNNs is through continuous experimentation and practical application. Start building, keep learning, and contribute to the exciting future of computer vision!
📚 References
Core Concepts and Architecture
Viso Suite. "Convolutional Neural Networks (CNNs): A Deep Dive." October 2024.
Nanyang Technological University. "Recent Advances in Convolutional Neural Networks." 2017.
upGrad. "CNN Architecture: 5 Layers Explained Simply." August 2025.
Lukmaanias. "Convolutional Neural Networks (CNN): An In-Depth Exploration." December 2024.
Technical Implementation
GeeksforGeeks. "Training of Convolutional Neural Network (CNN) in TensorFlow." December 2021.
SkillCamper. "How to Build Your First Convolutional Neural Network: A Step-by-Step Guide." May 2025.
Simplilearn. "CNN in Deep Learning: Algorithm and Machine Learning Uses." June 2025.
Victor Zhou. "Keras for Beginners: Implementing a Convolutional Neural Network." November 2020.
GeeksforGeeks & TensorFlow. Various CNN implementation guides.
upGrad. "Beginner's Guide for Convolutional Neural Network (CNN)." August 2025.
Architecture Comparisons
- GeeksforGeeks. "Convolutional Neural Network (CNN) Architectures." March 2023.
Latest Research
PMC. "Comparison of Vision Transformers and Convolutional Neural Networks." September 2024.
Nature. "Comprehensive comparison between vision transformers and CNNs." September 2024.
Recent comparative studies on CNNs vs Vision Transformers.
Applications
- PMC. "Convolutional neural networks in medical image understanding." January 2021.



